
背景
我们有一个java系统,需要从固定的文件目录中读取csv格式的文件,然后将文件内容读取后在进行一系列的转换以及数据库操作,包含文件内容转换为java对象、内容去重、查询oracle、生成目标数据集合、数据存入oracle和mongodb。
起初,文件目录中有四个文件,一个4.3G,另外三个都是几百兆,四个文件一起有5.3G,大约1200万条初始数据。
程序之前使用的文件都比较少,因此之前设置的主要jvm参数是-Xms64m -Xmx64G -XX:NewRatio=1 -XX:+UseConcMarkSweepGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/opt/,之前运行时也都很正常,但是这一次却几个小时都不结束。
问题排查和优化
第一次处理(以为发现新大陆,一番折腾还是无)
出现上边的问题,程序日志中却没有抛出异常,一直处在停顿状态。
由于缺乏这方面的经验,便只能常规的使用top以及free命令查看机器的内存以及cpu等状态,然后就发现在运行过程中当前进程的cpu占用持续保持400%-600%,很显然是不正常的。
看到这些数据,似乎就是因为cpu忙不过来,第一感觉可能是stream的问题,这套代码大量的使用了stream以及parallelStream,而parallelStream底层的ForkJoin实际是多线程处理。
于是使用cat /proc/cpuinfo| grep "cpu cores"| uniq查看了下机器的cpu信息,发现测试机是单核的cpu。
既然如此,那么是否真的就是因为单核导致的多线程不断切换,从而使cpu卡住呢?于是我把里边的parallelStream全部改成了stream。
令人失望的是,程序依旧是持续几个小时没有结果。
但是在这个过程中,却意外的在使用df -hl命令查看磁盘空间的时候,发现/opt/磁盘使用量飙升,一直到100%。
进一步跟踪后,发现在这个目录下产生了一个java_pid42156.hprof的文件,正是这个达到了几十G的文件耗尽了磁盘空间,而这个文件就是在程序内存溢出的时候记录相关信息的文件。
第二次处理(虽然结果已得出,但是问题未结束)
有了上边的新发现后,也就有了新的预测,猜测cpu持续300%-600%的现象很可能是因为内存溢出。
但是心中却依旧不太理解,仅仅5.3G的文件,Xmx都设置64G了,还能内存溢出?
疑问留在心中不能马上寻找答案,因为其他人等着测试结果,于是只能先简单粗暴的再jvm参数中增加内存,把Xmx64G改为了Xmx80G。
同时,考虑到内存不够时扩容问题,也一并把Xms改成了20G。
网上很多地方建议Xmx和Xms设置成一样的,但是考虑到这个程序每次运行后就会关闭,而每次的文件大小也都不一样,因此就没有设置为一样,避免小文件时也占用太大的内存。
通过这样的修改后,终于运行成功,最终得到了可以交付的数据。
但是呢,从开始运行到得到最终结果,这个程序却运行了6H15min,这是在是一个难以让人接受的时间。
更加诡异的是,在进行另一个目录的测试时,发现2.1G的文件却仅仅只需要不到8分钟。
5.3G和2.1G,数据量比例不到1:2.5,但是处理时间的比例确是1:46.8。
因此,尽管程序运行得到了最终结果,但是这个处理时间肯定是有问题的。
第三次处理(看似改善已很大,其实依旧不可行)
一时间,没有太好的思路,代码中也没有觉得可以优化的地方,抱着试一试的态度,再次增加内存,把Xmx加到了95G,再次运行的时候发现时间一下子从6H15min降到了1H40min。
性能一下子提升了四倍,看起来好像还可以吧,然而并不是。
这机器的总内存也就128G,真的能够就一下子给这个程序95G吗?
而且,1H40min,这个时间真的可以了吗?
答案都是,不行!
第四次处理(万般武艺皆用上,守得云开见月明)
既然不行,那就只能进一步分析,于是搬出了更多的工具,像top -Hp、printf、jstack,例如我某次运行的进程id是117325:
使用
top -Hp 117325找到了占用cpu资源最高的子进程id,例如117345;然后使用
printf %x 117345把这个id转换为16进制1ca61;然后使用
jstat 117325 |grep -A 200 1ca61
上边的输出结果中,看到有大量的GC Thread相关内容,于是进一步使用命令jstat -gcutil 117325 1000 30查看gc情况。
这不看不知道,一看吓一跳,在已经运行的50分钟里,gc时间就占了38分钟。
再进一步细看,YGC仅仅发生了十几次后就不再发生,也仅仅占用了50秒,而FGC则发生了三百多次,消耗了两千多秒,这怎么看都是不合理的。
不明白是什么原因导致发生了这么多的FGC,但是通过了解相关技术点,我大概了知道了什么情况下会触发FGC,用一个不太准确的说法,就是jvm中老生代不够用了。(FGC有一些配置会影响FGC的触发,所以不能单纯的说老生代,例如阈值)
既然如此,能否把老生代加大呢?
如果有了解jvm参数的,应该会注意到我开头提到的一个设置,即-XX:NewRatio=1,这个参数实际就是设置的老生代和新生代的比例,很显然这里是设置的1:1。
我不太清楚之前为什么会被设置为1,但是我知道如果我希望增大老生代,那么我可以增大这个值,于是我就改成了-XX:NewRatio=2。
让人欣慰的是,在Xmx依旧是95G时,程序再次运行,终于从1H40min变成了26min。
在不考虑内存合不合适的情况下,起码这个时间是可以接受的了。
第五次处理(果然望山跑死马,以为要到实不达)
时间可以接受了,但是内存是肯定不能接受的,于是只能进一步优化,先尝试着把Xmx95G改成了Xmx80G,NewRatio依旧是2。
但是悲哀的是,这次却运行了5H55min。
第六次处理(山重水复疑无路,柳暗花明又一村)
上边结果有些悲哀,但是事情却不能就此停止。
于是我进行了简单的计算,算到在95G内存时、-XX:NewRatio=2的情况下,老生代应该是63G,那么能否让最大80G的时候老生代也达到63G呢?
既然是可以配的,理论上当然可以,于是想到就做,再次通过简单计算后,我把-XX:NewRatio=2改成了-XX:NewRatio=4,这种情况下老生代最大应该是64G。
让人有点小兴奋的是,当做了上边的修改后,再次运行程序,一下子从5H55min变成了30min。
在兴奋的同时,我似乎找到了一点点规律,这样看起来,是否是保证老生代63G左右就可以了呢?
于是我进一步减少Xmx的配置,同时修改-XX:NewRatio,然后就发现,当Xmx75G、-XX:NewRatio=5时,也只需要29min,这时候算下来的老生代最大是62.5G。
第七次处理(惶恐滩头叹惶恐,零丁洋里叹零丁)
我终于松了一口气,也进一步确定了那个想法,只要我让最大老生代能达到63G左右,应该就可以了。
然而,我又被无情的打脸了,当我把Xmx降到70G,NewRatio也设置成9的时候,得到的却是java.lang.OutOfMemoryError: Java heap space。
当我把Xmx继续加到72G的时候,依旧是java.lang.OutOfMemoryError: Java heap space。
我的脸色,瞬间难看到了几点,因为我们的目标,是64G,,甚至更低。
第八次处理(路漫漫其修远兮,吾将上下而求索)
似乎,从jvm参数层面已经到了再也无法优化的地步,怎么办?
好像只能从代码层面下手了。
可是代码层面,那是最最开始就想要下手的地方,正是因为感觉无法下手,然后才有了之后的一系列jvm参数的优化。
怎么办?于是我又用上了其他的工具,像jProfiler、jvisualvm。
为了测试,我在本地把文件缩小到了770m,然后在工具中会看到类似下图的数据:

可以明显的看到整个过程中内存使用一直呈现上升趋势,期间时不时的下降,一直到持续占用8G左右的内存。
经过分析发现,每一次的下降实际就是发生了gc。
但是尽管一直在发生着gc,程序占用的内存依旧是在不断的上升着。
到底是为什么呢?
能想到的情况无非两种,要么是有什么大对象一直存在着不能被销毁,要么就是产生了很多不能被回收的对象。
到底是什么对象或者说是哪些对象呢?于是我在jvisualvm中打开了heapdump,然后就看到了类似下图的内容:
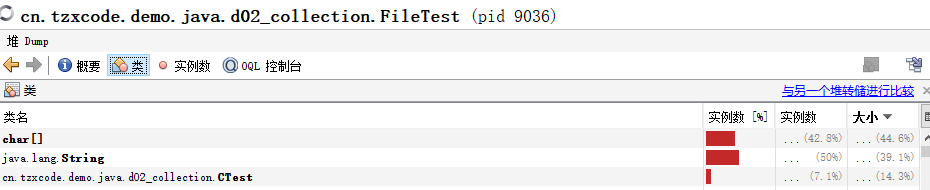
之所以说是类似,是因为公司电脑的截图我没法拿来用,本地并没有模拟一模一样的数据,结构也是相似,所以实际大小也有区别。
实际char[]是2972483224byte,约等于2.77G;
String是2792366808byte,约等于2.6G;
等同于CTest的是2391236928byte,约等于2.22G;
还有Double是398539560byte,约等于0.37G;
Integer的120736400byte,约等于0.11G。
前边这几个内存多的加起来就已经8G。
而关键性的代码是这一行:
1 | List<CTest> ll=getFiles1().stream().map(FileTest::createObject1) |
实际上一直存活的最终对象就是这个List
但是分析CTest类的定义会发现,里边有12个String属性,有1个Double属性,还有2个Integer属性。
这样看起来,似乎都对上了,但是这时候我头脑短路,始终想不明白为什么占用最多的是char[],这个类中没有定义char[]啊,甚至我一度陷入误区的认为是在io流处理的过程中生成了char[]对象,且莫名其妙的没有释放。
就这样焦头烂额好一阵子后,突然像是顿悟般,才想起来我竟然忽略了String的底层就是char[],如果这样看,似乎全都说的通的,所有占用大量内存的类都能找到归属了。
如果按这个比例粗略的计算,770m源文件最终出来的是8G的java对象,那么5.3G就是56G。
这样看来,似乎目前的程序便只能是Xmx75G、NewRatio=5这样了,是真的只能这样了吗?一时间又没有了头绪。
同时,脑海中也有了新的疑问:String和String底层的char[]竟然会同时占着各自的内存?难道不是String仅仅指向数组的引用吗?有点颠覆了认知。
