使用
通过前边的学习,服务注册中心、服务提供者和服务消费者都成功建立并运行起来,而且通过默认的配置restTemplate及@loadbalanced注解开启了负载均衡。
在默认的情况下,负载均衡策略是线性轮询的方式,也就是说在客户端获取到的服务列表中依次交替,例如开启了三个服务server1、server2、server3,那么在线性轮询时,就会按这个顺序来调用。
我之前是开启了两个服务,一个端口是1001,另一个是2001,那么在之前的这种情况下,如果我关闭其中一个服务,就比如这里关闭1001端口的服务,当再次访问的时候,每访问两次,就会有一次是如下的error page:
Whitelabel Error Page This application has no explicit mapping for /error, so you are seeing this as a fallback. Fri May 26 09:31:57 CST 2017 There was an unexpected error (type=Internal Server Error, status=500). I/O error on GET request for "http://HELLO-SERVICE/hello": Connection refused: connect; nested exception is java.net.ConnectException: Connection refused: connect
同时后台也会打印出错误日志:
java.net.ConnectException: Connection refused: connect
at java.net.DualStackPlainSocketImpl.connect0(Native Method) ~[na:1.8.0_131]
at java.net.DualStackPlainSocketImpl.socketConnect(Unknown Source) ~[na:1.8.0_131]
at java.net.AbstractPlainSocketImpl.doConnect(Unknown Source) ~[na:1.8.0_131]
at java.net.AbstractPlainSocketImpl.connectToAddress(Unknown Source) ~[na:1.8.0_131]
at java.net.AbstractPlainSocketImpl.connect(Unknown Source) ~[na:1.8.0_131]
at java.net.PlainSocketImpl.connect(Unknown Source) ~[na:1.8.0_131]
at java.net.SocksSocketImpl.connect(Unknown Source) ~[na:1.8.0_131]
at java.net.Socket.connect(Unknown Source) ~[na:1.8.0_131]
其实这个问题的原因就是,客户端的服务列表并不是在服务关闭的瞬间就会同步更新,而是根据它自己配置的更新服务列表间隔的时间每隔一段时间去注册中心获取一次。
因此,虽然这里我关闭了1001端口,但是实际上客户端并不知道,在它负载均衡进行线性轮询时,依旧会轮询之前保存的服务列表,但是发送请求后却发现这个服务实例并不存在,无法连接,于是就出现了上边的500错误。
这里为了演示,我是主动关闭了服务,但实际生产的过程中,难免会出现服务宕机或者网络故障等方面的问题,从而导致类似的无法连接到服务实例的情况。
那么这时候正常来说在这个故障恢复之前是不应该继续连接的,起码就算连接了也应该给用户展示更加友好的界面或其他信息,至于具体的情况就需要具体对待了。
而解决这个问题,就引出了服务容错保护机制Hystrix,也叫断路器。
既然之前说了消费方保存的服务列表是自己主动获取的,并非被动推送来的,那么可想而知这个断路器的定义也应该是在服务消费方。
首先需要引入hystrix相应的依赖,在之前的消费端pom.xml的基础上加上如下的配置:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-hystrix</artifactId>
</dependency>
同时在服务消费端的主类加上@@EnableCircuitBreaker注解,这个注解的作用就是开启断路器功能,所谓的主类就是具有main方法的那个类,修改之后这里的代码如下:
@EnableCircuitBreaker
@EnableDiscoveryClient
@SpringBootApplication
public class RibbonClient1Application {
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(RibbonClient1Application.class, args);
}
}
这里实际上有一点需要说明的是,这个类上边的三个注解其实是可以用一个注解代替的,这个注解是@SpringCloudApplication,通过源码可以知道这个注解包含了上述三个注解,也意味着一个标准的springcloud应用是应该包括服务的注册发现以及断路器功能的。
那么除开主类加一个注解之外,原本的服务类也需要有一定的修改,首先是在原本调用的方法上加上@HystrixCommand(fallbackMethod = “helloError”),意思是当调用的服务出现故障的时候回调helloError方法,或者说当调用服务出现故障的时候回滚一步,然后转而调用helloError方法。
不管怎样,既然要调用helloError方法,很显然需要存在这个方法,因此还需要加入一个helloError方法,当然了这个方法名是自定义的,里边的逻辑也是要根据具体的业务需要定义的,我这里就很简单的返回一个字符串,修改之后的代码如下:
@RestController
public class ConsumerController {
@Autowired
RestTemplate restTemplate;
@RequestMapping(value="/hello",method=RequestMethod.GET)
@HystrixCommand(fallbackMethod = "helloError")
public String hello(){
String string = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
System.out.println(string);
return string;
}
public String helloError() {
return "服务器出现故障";
}
}
就这样,一个简单地断路器功能就实现了,为了证明确实有效,我在两个服务正常运行的情况下再次关闭其中一个,然后再在浏览器访问的时候就不会再出现之前的500提示,后台也同样不再有error的日志,证明成功的处理了的这种故障,浏览器访问结果如图: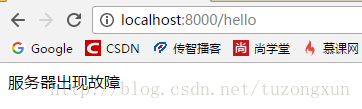
当然了,我这里演示的时候,为了方便都是直接关掉了其中一台服务器,这相当于实际生产中的服务器突然宕机或者进程突然中断的情况,而实际上这种情况发生的几率还是比较少的。
由于在分布式高可用的系统中,一般不同的服务是部署在不同的服务器上,不同的服务器间就会涉及到网络通讯和数据传输,因此正常来说网络故障导致服务异常的情况会更多一些。
如果要演示这种情况,就可以在服务接收请求到返回数据之前加入线程休眠,从而模拟网络阻塞,只需要注意hystrix的默认超时时间是2000毫秒,也就是2秒就够了。
运行流程说明
流程图(来自网络)
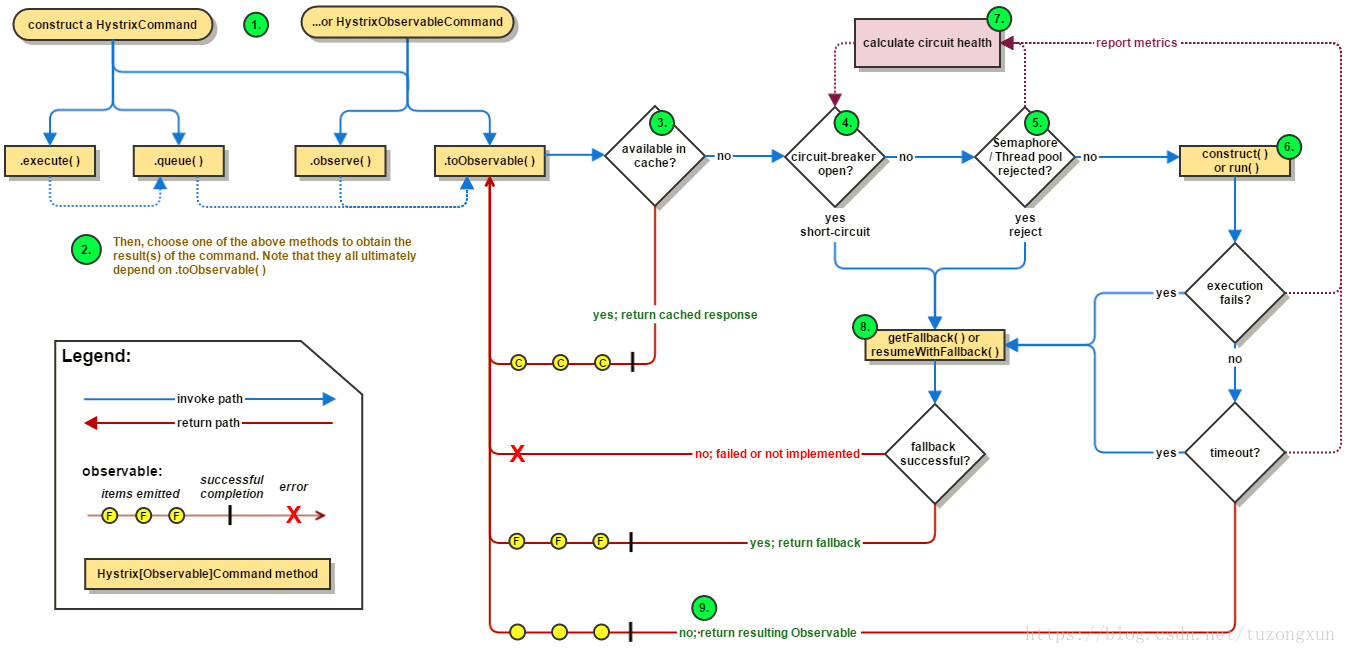
流程说明
hystrix运行流程说明:
- 每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
- 执行execute()/queue做同步或异步调用.
- 判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤.
- 判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤.
- 调用HystrixCommand的run方法.运行依赖逻辑
5a:依赖逻辑调用超时,进入步骤8. - 判断逻辑是否调用成功
6a:返回成功调用结果
6b:调用出错,进入步骤8. - 计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
- getFallback()降级逻辑.
8a:没有实现getFallback的Command将直接抛出异常
8b:fallback降级逻辑调用成功直接返回
8c:降级逻辑调用失败抛出异常 - 返回执行成功结果
fallback触发场景
综合上边的流程可知,四种情况将触发getFallback调用:
(1):熔断器开启拦截调用
(2):线程池/队列/信号量是否跑满
(3):run()方法调用超时
(4):run()方法抛出非HystrixBadRequestException异常
如何判断熔断器是否打开:
(1):熔断器打开标示,为true为打开,否则查询度量指标(10s的时间窗)
(2):请求阀值是否超标,默认是20个请求,超标则为true
(3):请求错误百分比是否超标,默认是50,超标则为true
当2和3都超标时,熔断器标示会设为true,打开状态。
依赖隔离
默认是线程池隔离,可以改成信号量。
信号量开销比线程池小很多,但不支持异步访问和设置超时。
